Attention in transformers, visually explained | Chapter 6, Deep Learning
null
Click
Use
to move to a smaller summary and to move to a larger one
The Attention Mechanism in Transformers
- The attention mechanism is a key component in transformers, which are used in large language models and AI tools.
- Transformers were introduced in a 2017 paper called "Attention is All You Need."
- The goal of the model is to predict the next word in a piece of text.
- Tokens are used to represent words or pieces of words in the input text.
- Each token is associated with a high-dimensional vector called its embedding.
- Directions in the embedding space correspond to semantic meaning.
- The attention mechanism allows for the adjustment of embeddings to capture contextual meaning.
- The attention mechanism can be confusing, but it enables behavior such as understanding different meanings of a word based on context.
- The surrounding embeddings pass information into the current embedding in the transformer.
- The attention block calculates what needs to be added to the generic embedding to move it in a specific direction based on the context.
- The attention block allows for the movement of information between embeddings and the enrichment of meaning beyond a single word.
- The attention mechanism is used in multiple attention blocks throughout the transformer network.
Attention Blocks and Embeddings in Deep Learning
- The final vector in a sequence needs to encode all relevant information from the full context window.
- The attention block consists of multiple heads running in parallel.
- Initial word embeddings encode the meaning and position of the word.
- The goal is to refine embeddings so that they capture the meaning from corresponding adjectives.
- Matrix-vector products with tunable weights are used for most computations.
- An example is given of adjectives updating nouns through attention heads.
- The query vector represents a word's question about the presence of adjectives.
- The query vector is computed by multiplying a matrix with the embedding.
- The query matrix maps noun embeddings to directions that encode the search for adjectives.
- The behavior of the query matrix for other embeddings is not specified.
Attention Mechanism and Training Process in Transformers
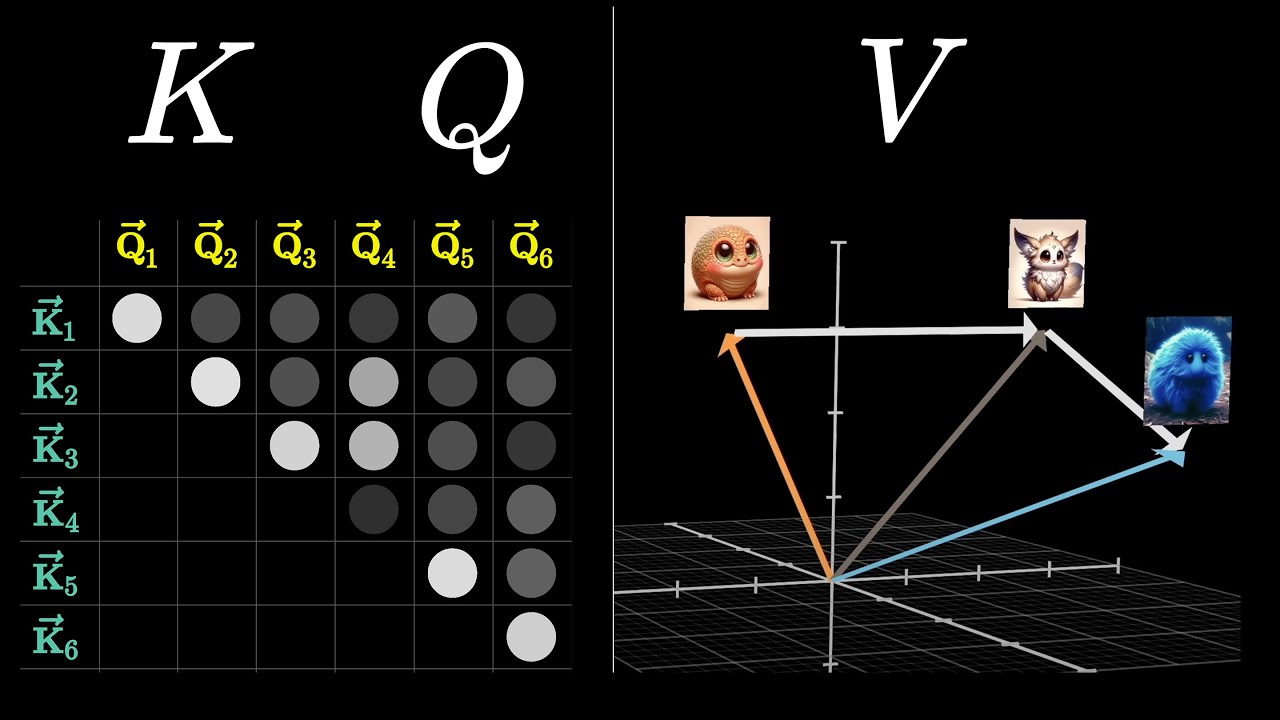
- The attention mechanism in transformers involves multiplying embeddings with a key matrix and producing a sequence of vectors called keys.
- The key matrix contains tunable parameters and maps the embeddings to a smaller dimensional space.
- The keys are considered to match the queries when they closely align with each other.
- The dot product between each key-query pair is computed to measure their relevance.
- The dot products represent the alignment between the keys and queries.
- The relevance scores are used to compute a weighted sum along each column.
- The values in the columns are normalized using softmax to ensure they range from 0 to 1 and add up to 1.
- The resulting grid is called an attention pattern and represents the relevance of each word in updating the meaning of every other word.
- During training, the model adjusts the weights based on how high a probability it assigns to the true next word.
- The training process is more efficient when the model simultaneously predicts every possible next token following each initial subsequence of tokens in the passage.
Attention Mechanism and Embedding Updates in Language Models
- Attention mechanism prevents later words from influencing earlier words in the model.
- The attention pattern is created by setting certain entries to negative infinity before applying softmax.
- Masking is applied to prevent later tokens from influencing earlier ones in the GPT example.
- The size of the attention pattern is equal to the square of the context size, which can be a bottleneck for large language models.
- Scaling up the context size is non-trivial and variations of attention mechanism have been developed to make it more scalable.
- Embedding updates allow words to pass information to other relevant words.
- The most straightforward way to update embeddings is by using a value matrix, multiplying it with the embedding of the first word to create a value vector, and adding it to the embedding of the second word.
- The value vector represents what should be added to the second word's embedding to adjust its meaning based on the relevance of the first word.
- The value matrix is multiplied with all the embeddings to produce a sequence of value vectors associated with the corresponding keys.
Parameters and Structure of Attention Heads
- The attention block consists of a sequence of changes applied to embeddings.
- The process is parameterized by three matrices: key, query, and value.
- The key and query matrices have 12,288 columns and 128 rows.
- The value matrix is factored into two smaller matrices: value down and value up.
- The value down matrix maps large embedding vectors to a smaller space.
- The value up matrix maps from the smaller space back to the embedding space.
- All four matrices have the same size, resulting in approximately 6.3 million parameters for one attention head.
- Self-attention heads are used in GPT models, while cross-attention heads are used for processing different types of data.
- Cross-attention involves keys and queries from different datasets, such as translation between languages or speech transcription.
Multi-Headed Attention in Transformers
- Context can influence the meaning of a word in different ways.
- Different types of contextual updating require different parameters in key, query, and value matrices.
- Multi-headed attention in transformers consists of running multiple operations in parallel, each with its own distinct key, query, and value matrices.
- GPT-3, for example, uses 96 attention heads in each block.
- Each attention head produces a proposed change to be added to the embedding in a specific position.
- The proposed changes from all heads are summed together and added to the original embedding to produce a refined embedding.
- Multi-headed attention allows the model to learn multiple ways that context changes meaning.
- Each block of multi-headed attention has around 600 million parameters with 96 heads.
- The value up matrices are combined into one giant matrix called the output matrix for the entire multi-headed attention block.
- When referring to the value matrix for a specific attention head, it typically means the value down projection into the smaller space.
The Role of Attention and Parameters in Transformer Models
- Data flowing through a transformer goes through multi-layer perceptrons in addition to attention blocks.
- The embedding of a word is influenced by its nuanced surroundings as it goes through multiple copies of these operations.
- The hope is that as the network goes deeper, embeddings capture higher-level and more abstract ideas beyond descriptors and structure.
- GPT-3 has 96 distinct layers, with a total of just under 58 billion parameters dedicated to attention heads.
- The majority of parameters in GPT-3 come from the blocks between attention steps.
- The success of attention lies in its parallelizability, allowing for a large number of computations in a short time using GPUs.
- Scale plays a significant role in improving model performance, and attention enables this through parallelizable architectures.
The Attention Mechanism in Transformers
- Transformers are used in large language models and AI tools.
- The attention mechanism is a key component in transformers.
- Tokens represent words or pieces of words in the input text.
- Each token is associated with a high-dimensional vector called its embedding.
- The attention mechanism allows for the adjustment of embeddings to capture contextual meaning.
- The attention mechanism enables understanding different meanings of a word based on context.
- The attention block calculates what needs to be added to the generic embedding to move it in a specific direction based on the context.
- The attention block allows for the movement of information between embeddings and the enrichment of meaning beyond a single word.
- The attention mechanism is used in multiple attention blocks throughout the transformer network.
- The final vector in a sequence needs to encode all relevant information from the full context window.
- The attention block consists of multiple heads running in parallel.
- Matrix-vector products with tunable weights are used for most computations.
- The attention mechanism involves multiplying embeddings with a key matrix and producing a sequence of vectors called keys.
- The dot product between each key-query pair is computed to measure their relevance.
- The relevance scores are used to compute a weighted sum along each column.
- The resulting grid is called an attention pattern and represents the relevance of each word in updating the meaning of every other word.
- The attention pattern is created by setting certain entries to negative infinity before applying softmax.
- Masking is applied to prevent later tokens from influencing earlier ones.
- Variations of the attention mechanism have been developed to make it more scalable.
- Embedding updates allow words to pass information to other relevant words.
- The attention block is parameterized by key, query, and value matrices.
The Role of Multi-Headed Attention in Transforming Contextual Meaning
- Different types of contextual updating require different parameters in key, query, and value matrices.
- Multi-headed attention in transformers runs multiple operations in parallel, each with its own distinct matrices.
- GPT-3 uses 96 attention heads in each block to propose changes to the embedding in specific positions.
- Multi-headed attention allows the model to learn multiple ways that context changes meaning.
- Each block of multi-headed attention has around 600 million parameters with 96 heads.